


Storage Architecture
Huawei joined CERN openlab as a contributor in 2012 and as a full partner in 2013 to cover the rapidly expanding area of cloud storage. The storage and management of LHC data is one of the most crucial and demanding activities in the LHC computing infrastructure at CERN and also at the many collaborating sites within the Worldwide LHC Computing Grid (WLCG). The four large-scale LHC experiments create tens of petabytes (PB) of data every year. This needs to be reliably stored for analysis in the CERN data centre and in many partner sites in WLCG. Today, most physics data is still stored with custom storage solutions, which have been developed for this purpose within the High-Energy Physics (HEP) community. As user demands increase (in terms of both data volume and aggregated speed of data access), CERN and its partner institutes are continuously investigating new technological solutions to provide more scalable and performant storage solutions to the user community. At the same time, CERN closely follows the larger market trends on the commercial side in order to continuously evaluate new solutions and to be ready for their adoption as soon as they have matured sufficiently for largescale deployment.
The recently emerged cloud storage architecture and its implementations may provide scalable and potentially more cost-effective alternatives. Native cloud storage systems, such as the Amazon Simple Storage Service (S3), are typically based on a distributed key-value store, and divide the storage namespace up into independent units called buckets. This partitioning increases scalability by insuring that access to one area (bucket) is unaffected by the activity in other parts of the distributed storage system. In addition, the internal replication and distribution of data replicas over different storage components provides intrinsic fault-tolerance and additional read performance: multiple data copies are available to correct storage media failures and to serve multiple concurrent clients. On the larger scale (across site boundaries), the HTTP-based S3 protocol has become a defacto standard among many commercial and open-source storage products. It may, therefore, become an important integration technology for consistent data access and exchange between science applications and a larger group of sites. One of the advantages of S3 is that the decision between operating a private storage cloud or using commercial cloud services is still left to the site, based on its size and local cost evaluation.
During recent years, Huawei has invested significantly in complementing their traditional storage offering with a cloud storage implementation. Their Universal Distributed Storage (UDS) system is based on a key-value store which clusters large numbers of inexpensive CPU-disk pairs to form a scalable, redundant storage fabric. Recent versions of the product provide several redundancy mechanisms ranging from basic replication to erasure encoding. This functionality is aimed at enabling storage providers to choose among different levels of data integrity, access speed and media overhead to match the requirements of different applications.
Evaluation
The CERN openlab Storage Architecture Competence Centre (SACC) team is evaluating a Huawei cloud storage prototype that is deployed in the CERN data centre with a storage capacity of 768 terabytes (TB). The system has two main functional components: front-end nodes and storage nodes. The front-end nodes are user-facing node which implement the S3 access protocol and delegate the storage functions to storage nodes. The storage nodes manage data and metadata on local hard disks. The setup at CERN consists of seven front-end nodes and 384 storage nodes, each storage node being a disk-processor pair comprised of a 2 TB disk coupled to a dedicated ARM processor and memory.
The Huawei cloud storage system is designed for handling large amounts of data. All stored objects are divided into one megabyte (MB) chunks, and spread and stored on the storage nodes. The evaluated setup uses three replicas to ensure the data availability and reliability. Data replicas are distributed to different storage nodes such that a loss of one complete chassis (i.e. 16 storage nodes) will not have impact on data availability. In case of a disk failure, an automated self-healing mechanism ensures that the data on the faulty disk is handled by the other storage nodes. Corrupted or unavailable data is replaced using the remaining replicas.
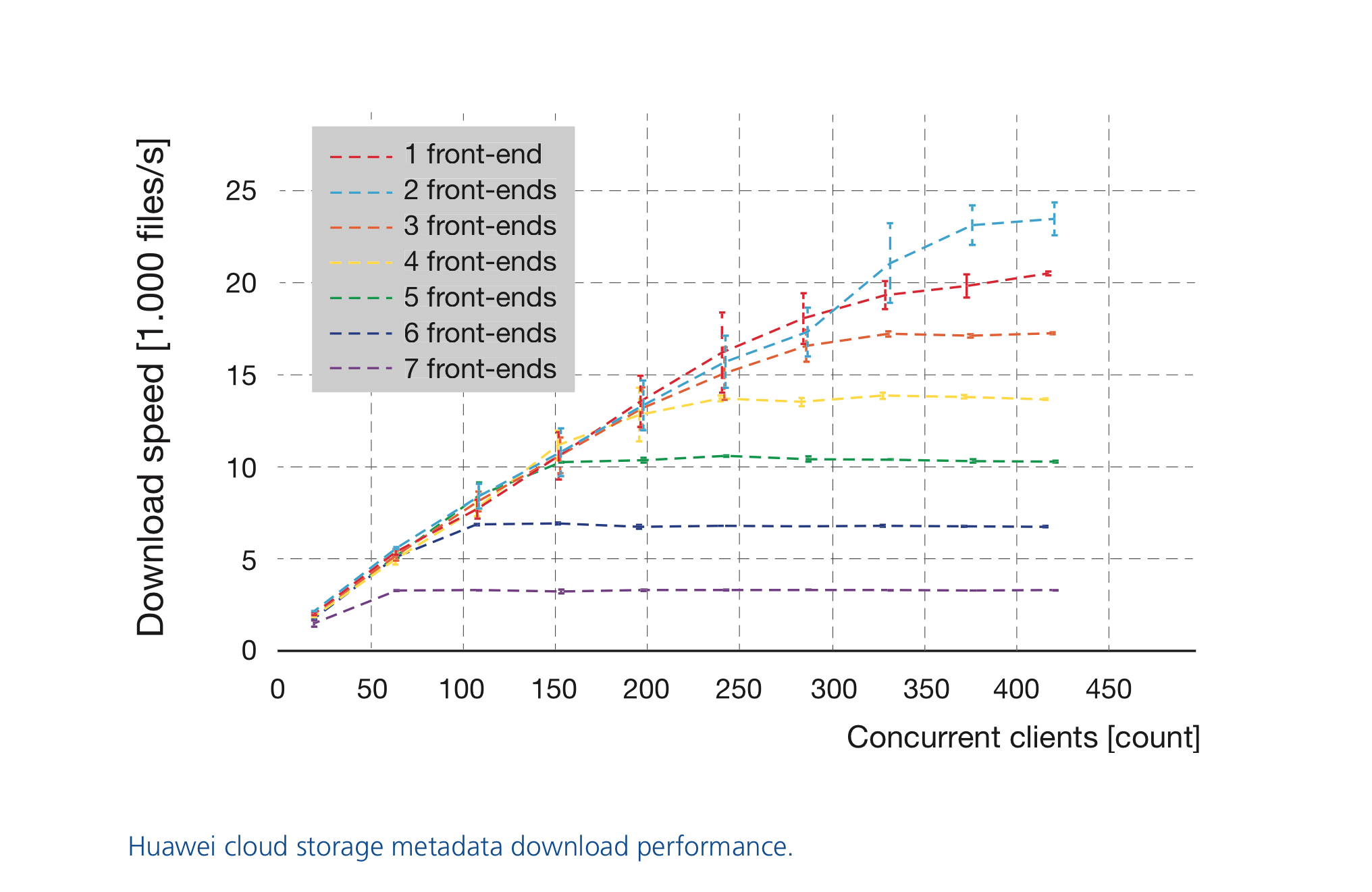
The SACC team evaluated the Huawei cloud storage performance with a S3 benchmark that was developed for this purpose. The benchmark master process deploys and monitors many parallel client processes via dedicated client machines. A large number of benchmarks were executed in different configurations to measure the aggregated throughput and rate of metadata operations. In order to study the metadata performance very small 4 kilobytes (KB) fi les were used. The small amount of payload data meant that any throughput-related constraints and stress were avoided, particularly with regards to metadata handling. In addition, the number of front-end nodes used was varied. The aim of this was to verify the capacity of each additional front-end node to add a similar amount of processing capability to the storage system.
Performance
The metadata download performance results are shown in the figure above. Each front-end node adds linearly around 3500 fi les per second to the total download rate. The achieved maximum 4 KB download performance could likely be further increased by simply adding more front-end nodes. The front-end nodes have not, however, been a limiting factor with 4 KB uploads. The maximum metadata upload performance was 2500 fi les per second when using around 1200 concurrent clients. The cloud storage throughput performance was measured using 100 MB files. With this payload size the upload performance is no longer strongly affected by the number of concurrently used buckets because the rate of metadata operations is several orders of magnitude lower. The upload and download throughput results show that the available network bandwidth of 20 gigabits could be filled easily. Each additional front-end node was able to download 1100 MB per second or upload 550 MB per second — until the network bandwidth limit was reached.
Failure recovery
The capability of the cloud storage system to recover transparently from sudden storage failures is one of the most desirable features for CERN. Indeed, if the system is able to recover automatically — including from major failures — the number of maintenance personnel readily available could be reduced. In order to study this recovery capability, the system was kept uploading and downloading actively while a power failure was simulated on one chassis by unplugging its power connection. The recovery test was executed for 500 seconds until the power was disconnected from one chassis containing 16 disks. The power was reconnected 300 seconds later.

The cloud storage failure recovery results are shown in the diagram. The affected clients, doing uploads and download on this chassis, experienced delays up to about 60 seconds, but no errors could be detected as all the read and write operations completed successfully. Further in the automated recovery process, a third vertical red line shows the point at which the first nodes became available again after the chassis was rebooted. Again, only delays and no errors were observed.
Another important aspect for CERN is the flexibility of the cloud storage system for serving the existing CERN services. It was important to understand if the required performance level could be achieved and if all the necessary storage system features were present. The first evaluation focused on CernVM File System (CVMFS), which is a fi le system that, among other applications, is widely used to distribute HEP software. The CVMFS system — with its cloud-storage back-end — was tested by simulating a publishing step of a software release consisting of 30,000 small fi les. The results show that the Huawei cloud storage back-end was able to publish around 1200 new fi les per second. This means that a new software release of this size could be achieved in just a few tens of seconds. The cloud storage has been behaving as expected and no major problems were found that would prevent the use of this cloud storage system for HEP data storage.
A second Huawei storage cloud was also recently installed in the CERN data centre. This new and more compact cloud storage system has 1.2 PB of storage space, consisting of 300 4 TB disks. The cloud storage’s S3 interface had been updated to support the latest S3 features, such as multi-part uploads. Next year, CERN openlab will focus on testing the performance of this new cloud storage system together with the older Huawei cloud storage installed in the data centre.

Previous activities for the Storage Architecture covering 2012 are available here.
Related content

![]()