





Database
In 2013, the Database Competence Centre (DCC) team continued the work started as part of the CERN openlab phase IV in six different areas: database technology, database monitoring, replication, virtualisation, operational data analytics, and physics data analysis in an Oracle database.
Database technology and monitoring
The DCC team has been very active in the area of database technologies (notably Data Guard, Application Continuity and Multitenant architecture) and has continued to work on the monitoring aspects in 2013. The work related to database technology involved a wide variety of tests performed as part of the 12c beta programme and in relation to the Oracle Multitenant Architecture. Application Continuity has also been a major focus for the team. Oracle Data Guard is used extensively at CERN for replicating data for functionality and disaster recovery. During the 12c beta program, functional and performance tests were performed. The objective of the functional tests was to check that basic operations work as documented and that there are no critical issues in the core functionality of the product. The performance tests looked at redo-apply lag statistics with different redo transport modes using a simulated workload. In the scope of the 12c beta testing, the DCC team validated Data Guard related components, with a special attention given to the new 12c features. In particular, the team thoroughly tested new Active Data Guard functionality including the Far Sync feature, the Fast SYNC redo transport mode, and the Data Guard broker. Thanks to the work done and the collaboration with Oracle, the production version of Oracle database 12c has implemented a number of Data Guard features matching CERN’s expectations for long distance efficient replication.
The Oracle Multitenant architecture enables the use of pluggable databases — one of the key features of the Oracle Database 12c release — which could integrate perfectly in the existing Database on Demand service. The DataBase on Demand service at CERN is a Platform as a Service (PaaS) oriented service providing database instances to users. The pluggable databases tests were concentrated on validating functionality, backup and recovery. The Multitenant Architecture is envisaged as part of the consolidation work planned at CERN. Work has been done to prepare the integration inside the Database on Demand service.
The new Application Continuity feature in the Oracle Database 12c solves a long-time complex issue with database applications: how to enable applications to recover from issues happening at the transport or database layer. Inversion 12c, Oracle has implemented a way to have the client and server sides keep a copy of the state so that it can be replayed in case it is required. Application Continuity tests were done in collaboration with the Controls group of the Beams department (BE CO) at CERN, in order to take advantage of an existing application — running in production — that could benefit from this new feature. The Java development team from the BE CO group created a replica of the production environment and tested Application Continuity by relocating services while the application was working. This has enabled the DCC to work together with the Oracle development team on real workloads and has proved that the feature can be used with very minimal changes in the application.
In the monitoring area, the DCC team kept working in 2013 on the integration of Enterprise Manager 12c with the existing infrastructure, the automation of tasks and extended the user base. The team upgraded to the latest release and integrated the authentication with the CERN Active Directory. They also took part in the Enterprise Manager Customer Advisory Board at the Oracle HQ in September and in the virtual Customer Advisory Boards that followed in order to share broadly within Oracle the work done at CERN through the openlab framework.
Virtualisation and replication
Virtualisation and replication technologies are important areas of work in the DCC. In 2013, Oracle VM has been tested for deployment against the CERN IT DB group requirements, while new features of Oracle products relevant to a database-oriented workload were also evaluated. In addition to traditional functionality testing and evaluation, special effort was dedicated to testing integration of the newest releases of both Oracle VM and Oracle Enterprise Monitor 12c. The main findings of this effort were a noticeable improvement in the variety and depth of monitoring metrics for Oracle VM when monitored using the Oracle Enterprise Monitor; and a complete study and analysis of virtual resource provisioning using the OEM 12c controlling interface. The suitability of the Oracle VM hypervisor as a virtualisation resource provider in an OpenStack deployment has also been studied. This is of high interest in the CERN IT environment since CERN now uses OpenStack as a cloud provider for its central computing services. Furthermore, Oracle products on virtual environments running on Oracle VM infrastructure are granted a certification. With this in mind, integration tests have been carried out targeting the current releases of the OpenStack platform (named ‘Grizzly’ and ‘Havana’) and the development versions of what will become the next Oracle VM version.
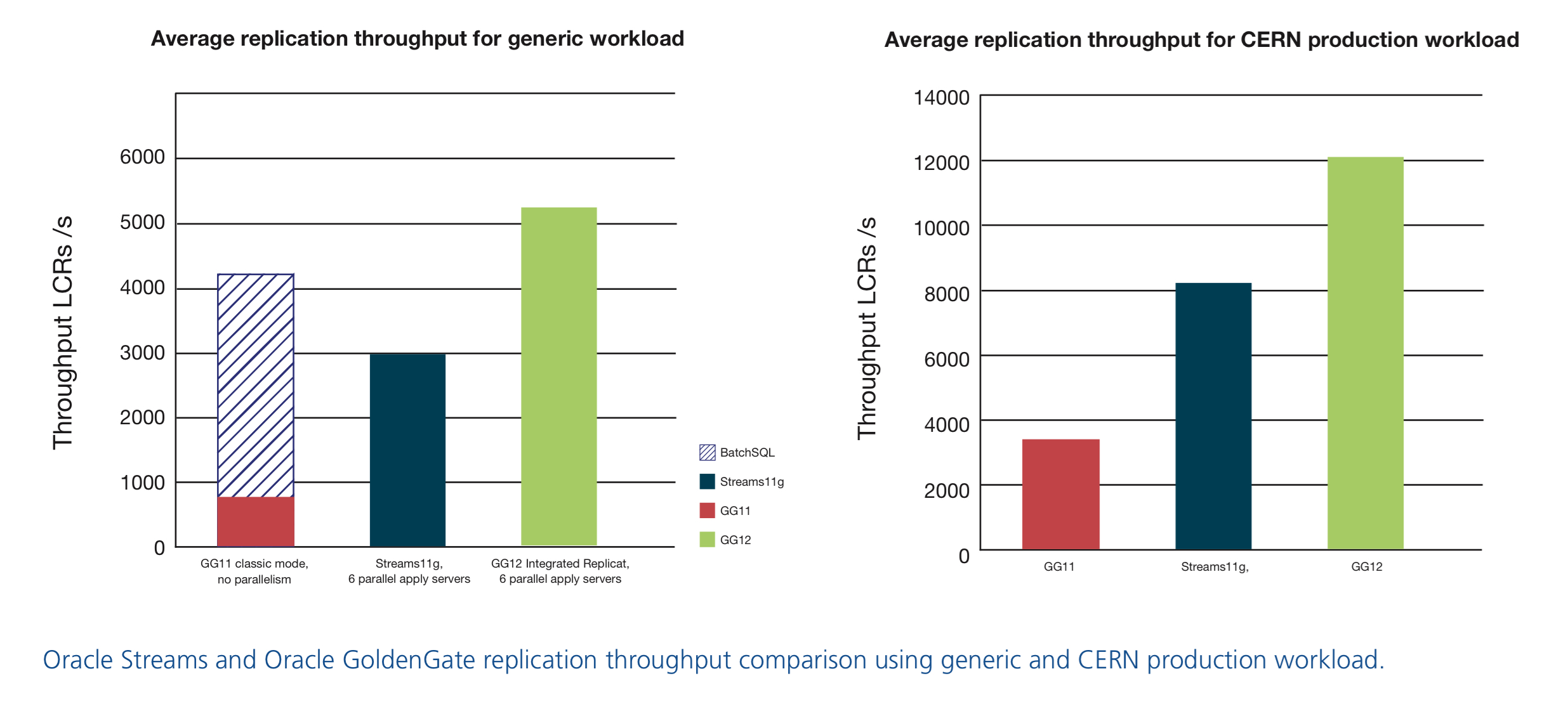
In the database replication area, 100 MB of data are being exchanged daily between CERN and the Worldwide LHC Computing Grid Tier-1 data centres with Oracle Streams. Supervising the correct functionality of this complex replication environment is a difficult task and has been the focus of significant development effort within CERN openlab in the previous years. Following the line of continuous quality improvement, new options for replication have been developed by Oracle, such as Oracle GoldenGate. The DCC team conducted various tests on the new release’s features to compare Oracle GoldenGate to Oracle Streams, with notable improvements obtained in monitoring, as well as for the overall throughput for replication. In addition, the team has been working with Oracle on new GoldenGate tools in order to provide dataflow monitoring and to reduce reaction time when facing possible issues. Veridata, GoldenGate Director, GoldenGate Monitor and OEM plugin have joined the replication area to achieve the maximum potential, stability and consistency of databases, which will be reflected in the production environment migration from Streams to GoldenGate programmed in 2014.
Data analytics
In the past years, huge amounts of monitoring and control data have been collected at CERN facilities and much more is expected in the coming years. Gathering, storing and visualising this data was a challenge by itself, which has been successfully addressed. The challenge now is to obtain additional value from all this data, developing intelligent, proactive and predictive monitoring and control systems driven by the analysis. From a theoretical point of view, understanding which models can be applied to extract value from the data for different use cases is crucial since there is no ‘magic black box’ which can perform this step automatically. As the literature suggests, application of the proper data-analytics approach can result in great improvements. Models for better understanding the performance, spotting the cause of the errors and detecting anomalies are just a few out of the short-term features which can be added on top of the monitoring and control infrastructures. The outcome of these models is the starting point for extremely interesting challenges in the medium term. In fact, by cross checking and correlating the results it becomes possible to find patterns and predict potential issues, thus enabling the development of early warning systems. However, infrastructure is key, as applying these models cannot be done using what was — until recently — the standard approach: a workstation running analysis software (such as in the R project for statistical computing) is today not powerful enough, given the volume of data. Moreover, given the growth of the monitoring and control data foreseen for the next years — in particular for the second run of the LHC — it is necessary to conceive a system capable of scaling out over the long term.
The first investigation stage, carried out in the context of the CERN openlab collaboration, has involved both open source and Oracle tools to evaluate the methodology, the models and the software solutions for performing advanced data analytics. The DCC studied the current CERN use cases and selected two of them as references: data monitoring of the CERN Advanced STORage manager (CASTOR) and real-time and in-database analytics system for the LHC control systems. For the data monitoring of CASTOR, the field-test permitted a first exploration of the tools and of the methodology, and provided positive results, which have been presented on several occasions at CERN to show the potential of advanced data analytics. The work with CASTOR is now moving to the predictive level, and an early warning system is being studied. Concerning the real-time and in-database analytics system for the LHC control systems, after a review of the requirements and use cases, the team selected and implemented a Proof of Concepts (PoC) based on the automatic detection of failures on the cryogenic valves. They achieved levels of accuracy above 80% and were able to detect overheating magnets by mean of an ensemble of machine learning and statistical models. The next step is to move from the PoC to the production environment and to address new use cases.
Attention has been paid on potential future challenges in terms of data analytics. Consequentially, in the near future other use cases will be embraced, in collaboration with various CERN departments: Engineering, Physics, Beams, Information Technology and potentially General Infrastructure Services. Network monitoring and intelligent workload distribution around the Worldwide LHC Computing Grid sites, IT monitoring, and CERN Accelerator Logging Service are just some of the possible fields of application of advanced data analytics at CERN facilities.
Physics analysis in an Oracle Database
This study looks at the possibility of performing analysis of the data collected by the LHC experiments through SQL-queries on data stored in a relational database. LHC analysis data is normally stored in, and analysed from, centrally produced ‘ROOT’ n-tuple fi les that are distributed through the Worldwide LHC Computing Grid. In the previous year, it was shown that a simplified physics analysis could be fully performed within an Oracle database, by re-writing the query in the form of SQL and using C++ libraries on the DB-machines linked via PL/SQL to be called within the analysis-query.
In March 2013, Oracle gave access for one week to an Exadata half-rack, which enabled testing of Exadata specific features with the In-Database Physics Analysis. Hybrid Columnar Compression (HCC) was shown to reduce the overall data-size by a factor of 3.2. Interesting challenges were identified when external functions are required in the selection. The benchmark analysis on two terabytes of data took 210 seconds on Exadata without compression and 135 seconds on the same data compressed with HCC.
A five-machine test-cluster was prepared that could run both Oracle and Hadoop. A Hadoop-version of the physics analysis benchmark was made by storing the analysis data in comma-delimited text-fi les in the Hadoop fi le storage system and by writing the analysis in the form of Map- and Reduce-classes in Java. CPU-overhead from the Hadoop framework caused relatively poor analysis times in this approach. The setup was also used to participate in the beta-testing of the new Oracle In-Database MapReduce feature. This feature enabled the MapReduce-code prepared for the Hadoop version of the analysis to be used to run on data stored in the Oracle database.
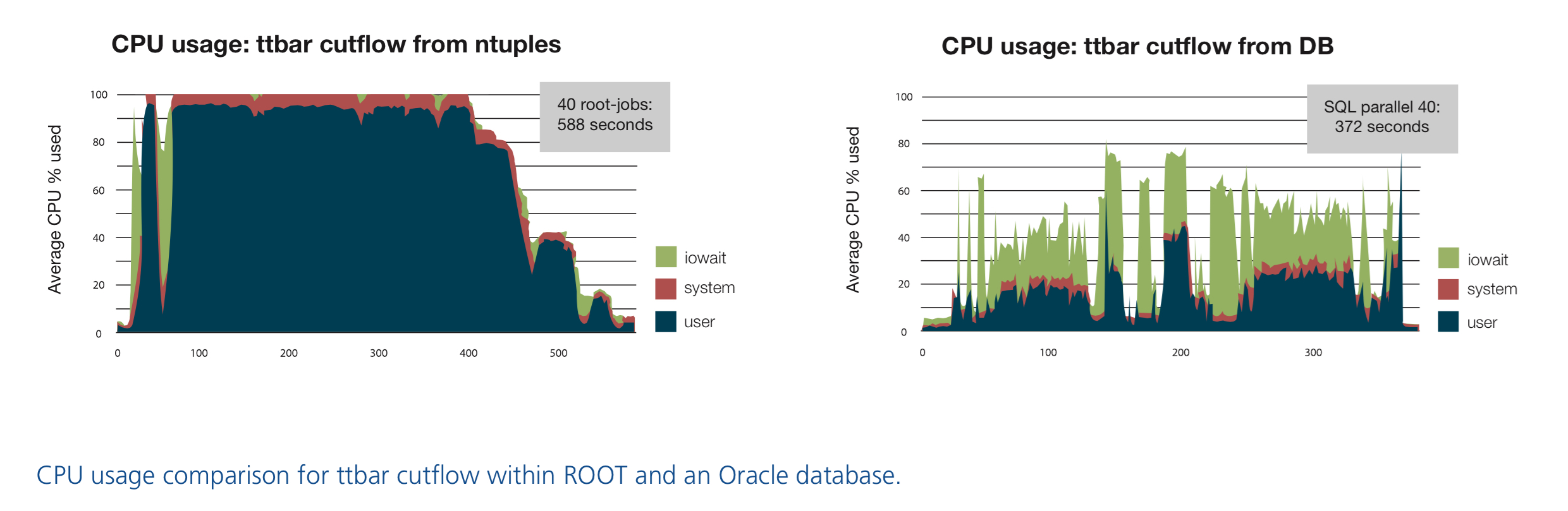
In order to provide a more realistic benchmark, the actual analysis code for performing ttbar cutflow, as written by the ATLAS top physics group, was converted into a SQL-based version. Compared to the simplified benchmark, this analysis used more analysis variables (277 variables compared to 35 variables in the simplified benchmark) and required more calculations through external libraries. On the five-machine test cluster running both ROOT and Oracle, the results depending on some of the parameters, with a degree of parallelism of 40, the analysis took 588 seconds for the ROOT-ntuple analysis and 372 seconds for the Oracle DB-version. The work was presented as a poster at the Computing in High-Energy Physics (CHEP) conference in Amsterdam in October 2013 and won the best-poster vote in its designated track. The conference proceedings that describe this work in detail have been published in a special online volume of the Journal of Physics: Conference Series by IOP Publishing (http:// iopscience.iop.org/1742-6596/513/2/022022).
Previous activities for the Database Competence Centre covering 2012 are available here. Further content can be found archived on the previous phases' website here
Related content
| Webcast: Governed Data Discovery as a Service - Better Decisions for More Efficient Operations at CERN |
| Video: The Zero Data Loss Recovery Appliance Experience at CERN |
![]()